
Kõik tõlkijad teavad, et mis tahes tõlketarkvara, näiteks Trados Studio, muudab tõlkimise lihtsamaks: kui ühe lause ära tõlgite, võetakse see aluseks kõikide sarnaste lausete tõlkimiseks, rääkimata sellest, et sama lauset pole vaja enam kunagi üheski tekstis uuesti tõlkida. Tõlgitud sõna või fraasi leiate kiiresti, klõpsates klahvi F3. Aga me soovime alati rohkem ja kiiremini. Tõlkemälu ligilähedased vasted on nagu nad on, kuigi näiliselt on mälu ja terminibaasid piisavalt suured, et pakkuda teie lausele paremat vastet. Aga enam ei pea raiskama aega ebatäpsete tõlgete parandamisele.
Novembris välja tulnud Trados Studio 2017 on järjekordne julge samm töö automaatseks muutmise suunas. Nüüd ei paku ligilähedased vasted ainult sarnaste varem tõlgitud lausete koopiaid. Nüüd parandab Trados Studio niisuguseid lauseid automaatselt.
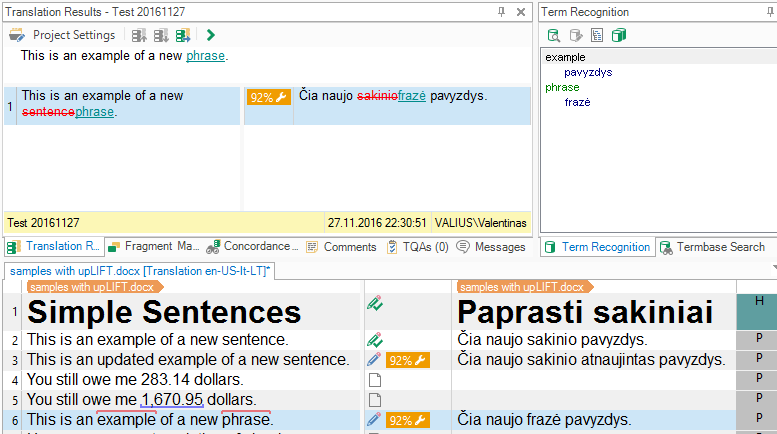
Vaatame kõigepealt lihtsaid näiteid. Kolmandas segmendis on lause, mis erineb teises segmendis olevast lausest ühe lisatud sõna võrra. Kui see sõna on andmebaasis olemas, on Trados Studiol teoreetiliselt olemas kogu vajalik teave selle lause automaatseks tõlkimiseks.

See toimub funktsiooniga upLIFT.

Trados Studio tõlkis kolmanda segmendi õigesti, kuigi vasteks näidatakse 92%. Mutrivõtme ikoon näitab, et see on funktsiooniga upLIFT tehtud automaatne tõlge.
Nii suudab programm peale sõnade lisamise neid ka asendada

Kuna sõna „frazė” on naissoost, tuleb muuta vaid lõppu.
Kui lähete edasi järgmise lause juurde, saate nautida funktsiooni upLIFT veel üht omadust – tõlgitud segmente kasutatakse soovitustena funktsioonis AutoSuggest; toodud näites on need sõnad „Simple Sentences”.

Fraase kasutatakse tõlkemälus ka ilma ligilähedaste vastete automaatse parandamiseta.

Peame vaid lisama käändelõpu ja lisama suurtähe.
Kui soovime kasutada varem tõlgitud segmenti mõnes teises lauses, saame väikese pettumuse osaliseks – Trados Studio ei paku sõna „Placeables” automaatset tõlget. See annab võimaluse vaadata projekti sätteid valikuga Project Settings. Klõpsake valikut Project Settings ja avanenud aknas laiendage valikut Language Pairs – All Language Pairs – Translation Memory and Automatic Translation, seejärel klõpsake käsku Search. Rühmas Segment Fragment Matching Options saate määrata lauseosa minimaalse pikkuse, mida Autosuggest kasutab. Vaikimisi on see väärtus 2. Kui määrate väärtuseks 1

ja klõpsate käsku OK, lähete tagasi tõlke juurde ja näete, et nüüd pakutakse sõna „Placeables” automaatselt.

Funktsioon upLIFT ei piirdu ligilähedaste vastete automaatsel parandamisel või vajalike sõnade pakkumisel terminibaaside ja tõlgitud segmentidega. Varem tõlgitud lausete osasid saab kasutada ka Autosuggesti jaoks; see tähendab, et programm analüüsib, kuidas on sõnu ja fraase varem tõlgitud, ning pakub tõlkeid uute lausete jaoks. Kuid selleks tuleb tõlkemälu enne ette valmistada.
Selle võimaluse illustreerimiseks ei loonud ma katsetamiseks tõlkemälusid ja tekste, vaid laadisin alla osa vabalt kättesaadavast tõlkemälust ELi kirjaliku tõlke peadirektoraadist. Märkasin, et neil on lauseid heitkoguste õigusaktist, ja üritasin tõlkida Wikipedia artiklit „European emission standards”. Kuid kõigepealt pidin mälu ette valmistama.
Tõlkemälu ettevalmistamiseks, selleks et see töötaks funktsiooniga upLIFT, avage see valikuga Translation Memories, paremklõpsake navigeerimisribal mälu nime ja valige käsk Settings.

Avanevas mälu parameetrite aknas valige suvnd Fragment Alignment. Valige rühma Fragment Alignment Status olekuks On, kui see pole juba valitud. Allpool jaotises Translation Model klõpsake valikut Build Translation Model. Tõlkemälu soovituslik suurus on vähemalt 5000 segmenti. Väiksemad mälud annavad väga ebausaldusväärse mudeli; mäludel, kus on vähem kui 1000 sõna, pole see nupp aktiivne.

Kui olete tõlkemudeli loonud, peate ühitama seosed mälus olevate sõnade ja fraaside vahel (mitte ainult lausete vahel). Seda saab teha allpool käsuga Align Translation Units

Nüüd on mälu valmis kasutamiseks funktsiooniga upLIFT. Laadime teksti Wikipediast Trados Studiosse ja näeme tulemust juba esimeses segmendis, kuid sõnade tõelist varakambrit näete eriterminitega laaditud lauseid tõlkides.

Tõlkemälu akna vahekaart Fragment Matches näitab kõiki sõnu ja fraase, mis on selle segmendi tõlkimiseks saadaval. Kui see teile huvi pakub (või kahtlete), võite iga sõna või fraasi klõpsata, et näha selle konteksti. Vahekaart sisaldab üsna palju teavet, nii et kasulik on see tõmmata välja eraldi aknasse või kasti.

Mina olen AutoSuggesti funktsiooniga harjunud – see säästab palju aega trükkimise arvelt. Kasutan tihti funktsiooni Concordance – see säästab aega sõnu, termineid või fraase otsides; kuid nende kopeerimine tõlkesse võib võtta aega, ja kuna seda tuleb sageli teha, muudab see töötamise üsna aeglaseks. Võiks öelda, et funktsioon upLIFT on AutoSuggesti ja Concordance’i eeliseid tugevdanud, ja see on kaua oodatud uuendus, mis vähendab veelgi käsitsi tehtava töö mahtu ja suurendab märgatavalt tootlikkust.
Näib, et on aeg unustada 30 aastat vana kopeerimis- ja kleepimistehnoloogia ning sundida arvuti tööle tõeliselt kiiresti. Saate ka SDL Trados Studio 2017 palju kiiremini osta veebisaidilt https://ee.cattool.eu/shop , saatmata meile ja tegemata telefonikõnesid. Kui te just minuga rääkida ei taha – küsimustele vastan ma alati suurima hea meelega. 🙂